GREY BALLARD
High Performance Tensor Computations
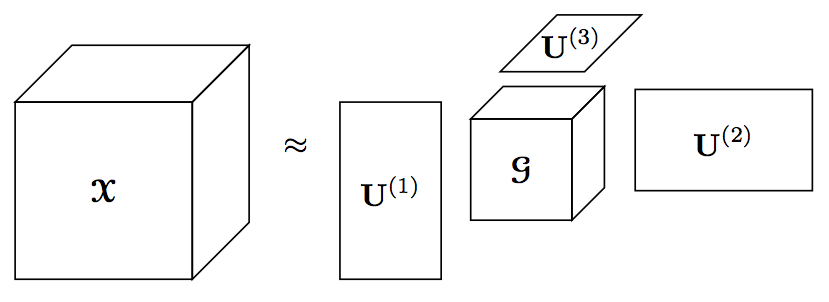
Advances in sensors and measurement technologies, extreme-scale scientific simulations, and growing digital communications all contribute to a data avalanche that is overwhelming analysts. Standard data analytic techniques often require information to be organized into two-dimensional tables, where, for example, rows correspond to subjects and columns correspond to features. However, many of today's data sets involve multi-way relationships and are more naturally represented in higher-dimensional tables called tensors. For example, movies are naturally 3D tensors, communication information tracked between senders and receivers across time and across multiple modalities can be represented by a 4D tensor, and scientific simulations tracking multiple variables in three physical dimensions and across time are 5D tensors. Tensor decompositions are the most common method of unsupervised exploration and analysis of multidimensional data. These decompositions can be used to discover hidden patterns in data, find anomalies in behavior, remove noise from measurements, or compress prohibitively large data sets. The aim of this project is to develop efficient algorithms for computing these decompositions, allowing for analysis of multidimensional datasets that would otherwise take too much time or memory.
This research is aligned with the Sparsitute, a Mathematical Multifaceted Integrated Capability Center (MMICC) funded by the US Department of Energy. Sparsitute brings together leading researchers across the nation working on various aspects of sparsity to accelerate progress and impact. Our ambitious research agenda will drastically advance the state-of-the-art in sparse computations both as a unified topic and within three broad pillars: sparse and structured matrix computations, sparse tensor problems, and sparse network problems, as well as their interconnections.
Relevant Papers/Talks
-
Workshop on Sparse Tensor Computations at the Discovery Partners Institute in Chicago, IL, 2023.
-
Minisymposium on Parallel Algorithms for Tensor Computations and their Applications at the SIAM Conference on Parallel Processing for Scientific Computing, 2022.
-
Minisymposium on
Algorithmic Advances in Tensor Decompositions at the SIAM Conference on Applied Linear Algebra, 2021.
-
Parallel Algorithms for CP, Tucker, and Tensor Train Decompositions keynote talk at the Workshop on Power-Aware Computing (PACO), 2019.
-
TuckerMPI: A Parallel C++/MPI Software Package for Large-scale Data Compression via the Tucker Tensor Decomposition.
Grey Ballard and Alicia Klinvex and Tamara G. Kolda.
ACM Transactions on Mathematical Software.
Volume 46, Number 2, Article 13. 2020.
-
A Practical Randomized CP Tensor Decomposition.
Casey Battaglino, Grey Ballard, Tamara Kolda.
SIAM Journal on Matrix Analysis and Applications.
Volume 39, Number 2, pp. 876–901. 2018.
-
Minisymposium on
High Performance Tensor Computations at the SIAM Annual Meeting, 2017.
-
Minisymposium on
Tensor Decompositions at the SIAM Conference on Computational Science and Engineering, 2017.
-
Minisymposium on
Parallel Algorithms for Tensor Computations at the SIAM Conference on Parallel
Processing for Scientific Computing, 2016.
Robust, Scalable, and Practical Low-Rank Approximation
for Scalable Data Analytics
Matrix and tensor low rank approximations have been foundational tools
in numerous science and engineering applications. By imposing constraints on the low rank
approximations, we can model many key problems and design scalable algorithms for Big Data
analytics that reach far beyond the classical science and engineering disciplines. In
particular, mathematical models with nonnegative data values abound across application
fields, and imposing nonnegative constraints on the low rank models make the discovered
latent components interpretable and practically useful. Variants of these constraints can
be designed to reflect additional characteristics of real-life data analytics problems.
The goals of this research are (1) to develop efficient
parallel algorithms for computing nonnegative matrix and tensor factorizations (NMF and
NTF) and their variants using a unified framework, and (2) to produce a software package
that delivers the high performance, flexibility, and scalability necessary to tackle the
ever-growing size of today’s data sets.
Relevant Papers/Talks
-
Parallel Nonnegative CP Decomposition of Dense Tensors.
Grey Ballard, Koby Hayashi, and Ramakrishnan Kannan.
Proceedings of the 25th IEEE International Conference on High Performance Computing, Data, and Analytics.
IEEE Computer Society, Washington, DC, USA, 22-31. 2018.
-
Minisymposium on
Constrained Low-Rank Matrix and Tensor Approximations at the SIAM Conference on Applied Linear Algebra, 2018.
-
MPI-FAUN: An MPI-Based Framework for Alternating-Updating Nonnegative Matrix Factorization.
Ramakrishnan Kannan, Grey Ballard, and Haesun Park.
IEEE Transactions on Knowledge and Data Engineering.
Volume 30, Issue 3, pp. 544-558. 2018.
Communication-Avoiding Algorithms
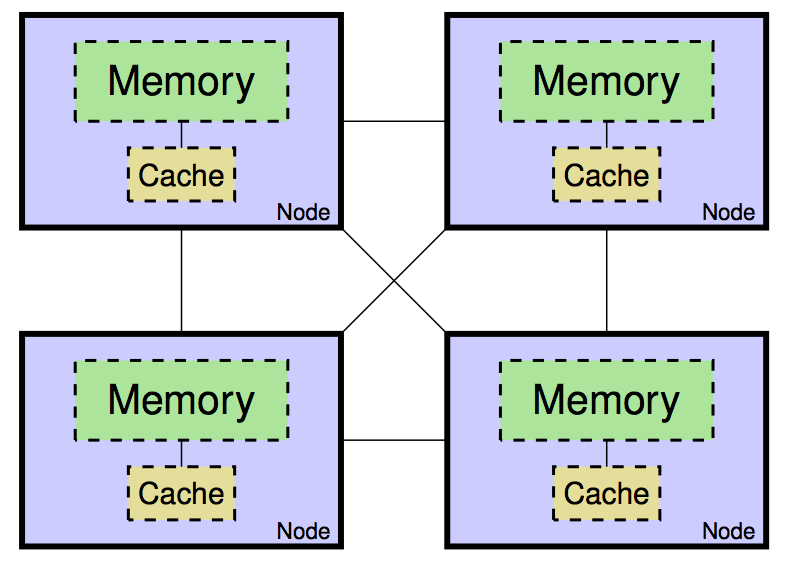
The traditional metric for the efficiency of an algorithm has been the number of
arithmetic operations it performs. Technological trends have long been reducing the time
to perform an arithmetic operation, so it is no longer the bottleneck in many algorithms;
rather, communication, or moving data, is the bottleneck. This motivates us to seek
algorithms that move as little data as possible, either between levels of a memory
hierarchy or among parallel processors over a network.
The idea of communication-avoiding algorithms is to reformulate existing approaches to
solving fundamental problems in order to significantly reduce the amount of data movement.
Using abstract machine models, we strive to prove communication lower bounds, determining
the minimum amount of data movement any algorithm must perform. Then we can compare the
communication costs of existing approaches to the lower bounds to determine if algorithmic
improvements are possible. If there exists a gap between best algorithm and best known
lower bound, the goal becomes to close the gap, usually with an innovative algorithm. In
this case, the ultimate goal is to implement the algorithm on state-of-the-art hardware to
achieve practical performance improvements for today’s applications.
Relevant Papers/Talks
-
General Memory-Independent Lower Bound for MTTKRP.
Grey Ballard and Kathryn Rouse.
Proceedings of the SIAM Conference on Parallel Processing for Scientific Computing.
pp. 1–11. 2020.
-
Communication Lower Bounds for Matricized Tensor Times Khatri-Rao Product.
Grey Ballard, Nicholas Knight, and Kathryn Rouse.
Proceedings of the 32nd IEEE International Parallel and Distributed Processing Symposium.
pp. 557-567. 2018.
-
Minisymposium on Communication-Avoiding Algorithms at the SIAM Annual Meeting, 2017.
Links to slides and talks can be found
here and
here.
-
Communication lower bounds and optimal algorithms for numerical linear algebra.
Grey Ballard, Erin Carson, James Demmel, Mark Hoemmen, Nicholas Knight, and Oded Schwartz.
Acta Numerica.
Volume 23, pp 1-155. 2014.
-
Hypergraph Partitioning for Sparse Matrix-Matrix Multiplication.
Grey Ballard, Alex Druinsky, Nicholas Knight, Oded Schwartz.
ACM Transactions on Parallel Computing.
Volume 3, Issue 3, pp. 18:1–18:34. 2016.
Practical Fast Matrix Multiplication
Strassen surprised the field of computer science in 1969 with a simple recursive algorithm
for dense matrix multiplication that requires asymptotically fewer arithmetic operations
than the traditional approach. For multiplying two square matrices of dimension n, his
algorithm requires O(n2.81) operations, while the traditional dot-product based algorithm
requires O(n3). His discovery sparked decades of research into “fast” matrix
multiplication algorithms in the fields of pure mathematics, theoretical computer science,
and high performance computing that continues today. There exists a theoretical goal of
discovering ω, the true exponent of matrix multiplication, and at the same time,
there exists a practical goal of leveraging fast algorithms to benefit the many
applications that rely on dense matrix multiplication as a computational kernel.
The goal of this project is to connect the theoretical and practical research on the topic
to discover and implement practical fast algorithms so that they can benefit applications.
Strassen’s original algorithm has been demonstrated to decrease run times of matrix
multiplications of reasonable sizes, even compared against heavily tuned library
implementations of the classical algorithm. Recently, a wealth of new algorithms have
been discovered, and there is renewed interest both in demonstrating that these algorithms
are also practical and in using computer-aided search to discover new algorithms. While
this problem is one of the most intensely studied in computer science, modern computational
capabilities are opening up new possibilities for research breakthroughs.
Relevant Papers/Talks
-
Accelerating Neural Network Training using Arbitrary Precision Approximating Matrix Multiplication Algorithms.
Grey Ballard, Jack Weissenberger, and Luoping Zhang.
Proceedings of the 50th International Conference on Parallel Processing Workshops.
2021.
-
The Geometry of Rank Decompositions of Matrix Multiplication II: 3x3 Matrices.
Grey Ballard, Christian Ikenmeyer, J.M. Landsberg, and Nick Ryder.
Journal of Pure and Applied Algebra.
Volume 223, Number 8, pp. 3205–3224. 2019.
-
Discovering Fast Matrix Multiplication Algorithms via Tensor Decomposition talk presented at the SIAM Conference on Computational Science and Engineering, 2017.
-
Improving the Numerical Stability of Fast Matrix Multiplication Algorithms.
Grey Ballard, Austin R. Benson, Alex Druinsky, Benjamin Lipshitz and Oded Schwartz.
SIAM Journal on Matrix Analysis and Applications.
Volume 37, Number 4, pp. 1382-1418. 2015.
-
A Framework for Practical Parallel Fast Matrix Multiplication.
Austin Benson and Grey Ballard.
Proceedings of the 20th ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming.
pp. 42-53. 2015.
-
Communication Costs of Strassen's Matrix Multiplication.
Grey Ballard, James Demmel, Olga Holtz, Oded Schwartz.
Communications of the ACM.
Volume 57, Number 2, pp. 107-113. 2014.
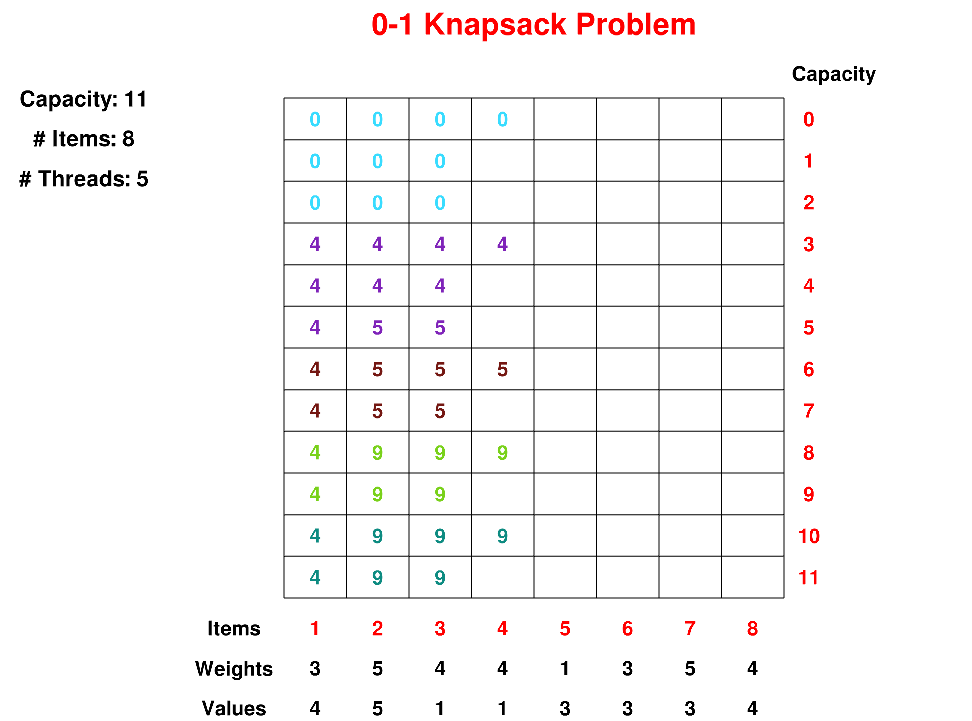
Visualizing Parallel Algorithms
The design and analysis of parallel algorithms are both fundamental to the set of high-performance, parallel, and distributed computing skills required to use modern computing resources efficiently.
In this project, we present an approach of teaching parallel computing within an undergraduate algorithms course that combines the paradigms of divide-and-conquer algorithms and dynamic programming along with multithreaded parallelization.
Using the Thread Safe Graphics Library, we have developed a set of visualization tools that enables interactive demonstration of parallelization techniques for two fundamental dynamic programming problems, 0/1 Knapsack and Longest Common Subsequence, and Mergesort.
The tools are publicly available to be used directly or as a basis on which to build visualizations of similar algorithms.
Relevant Papers/Talks